Core Concepts
This page describes the various components and assumptions made when constructing PayrollDetect. The goal is to understand how to model the uploaded data to optimize the use of PayrollDetect. The API schema for the data can be visualized below. In this page, the data is broken down into two categories: payslips and transactions.
PayrollDetect learns how the payroll for a specific employee, employee group (e.g., department) or company typically looks. When something deviates from the normal, PayrollDetect identifies the anomalies.
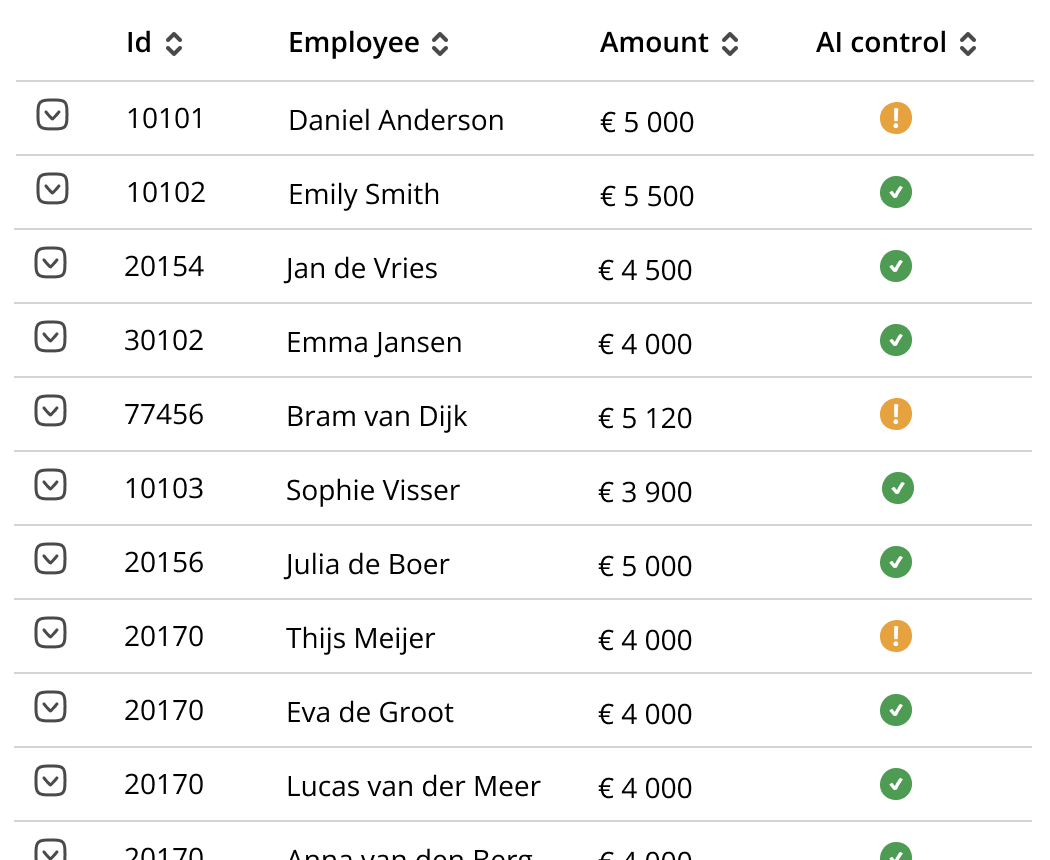
Payslips for different employees with anomolous payslips highlighted
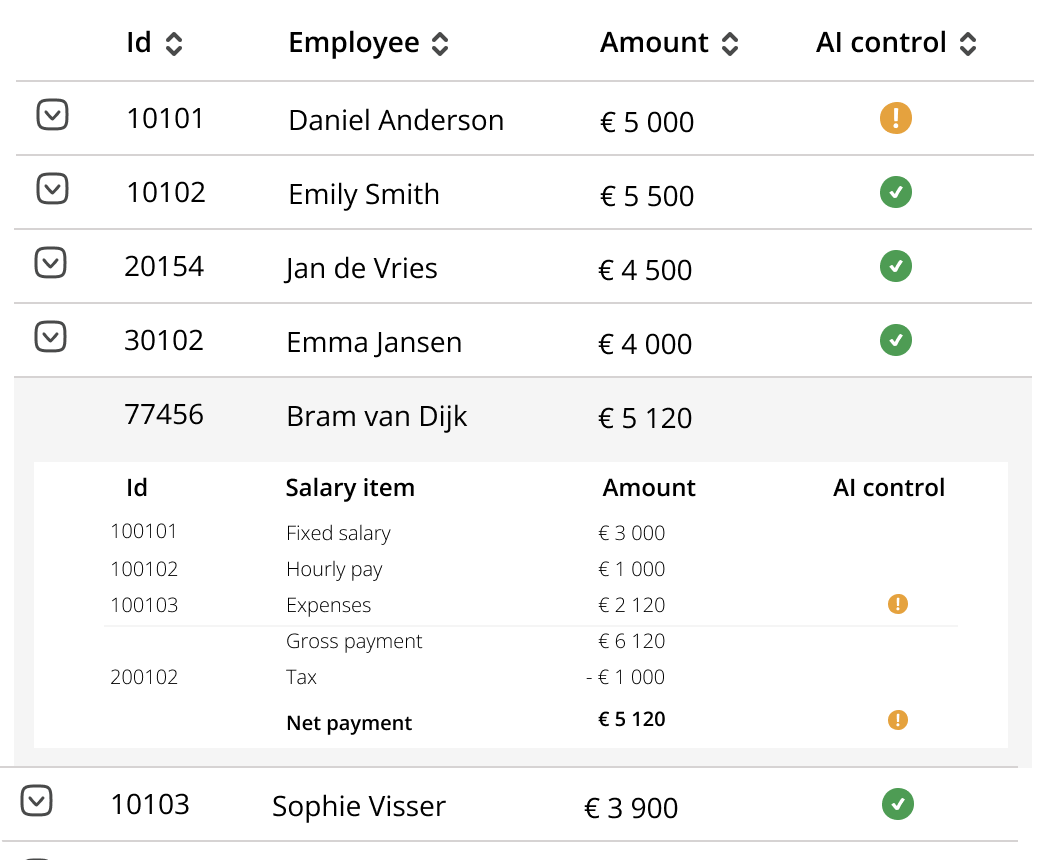
Transactions of a payslip with anomalies highlighted
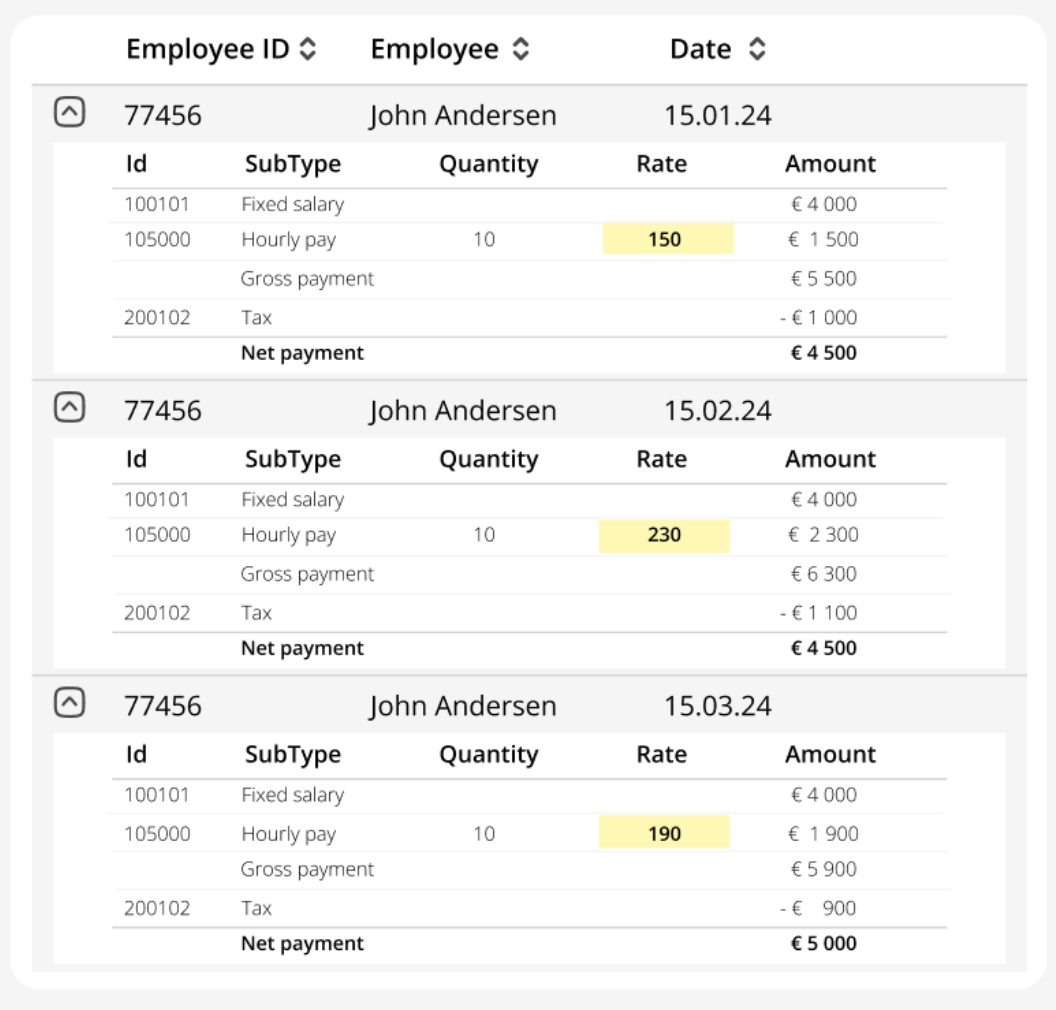
To correctly identify anomalies, it is crucial that data is submitted with consistent form across training (upload) and predicitons (e.g., consistent level of aggregation, similar SubTypes and handling of missing/null-values).
Below are some examples of violations of this.
Unmatched SubTypes
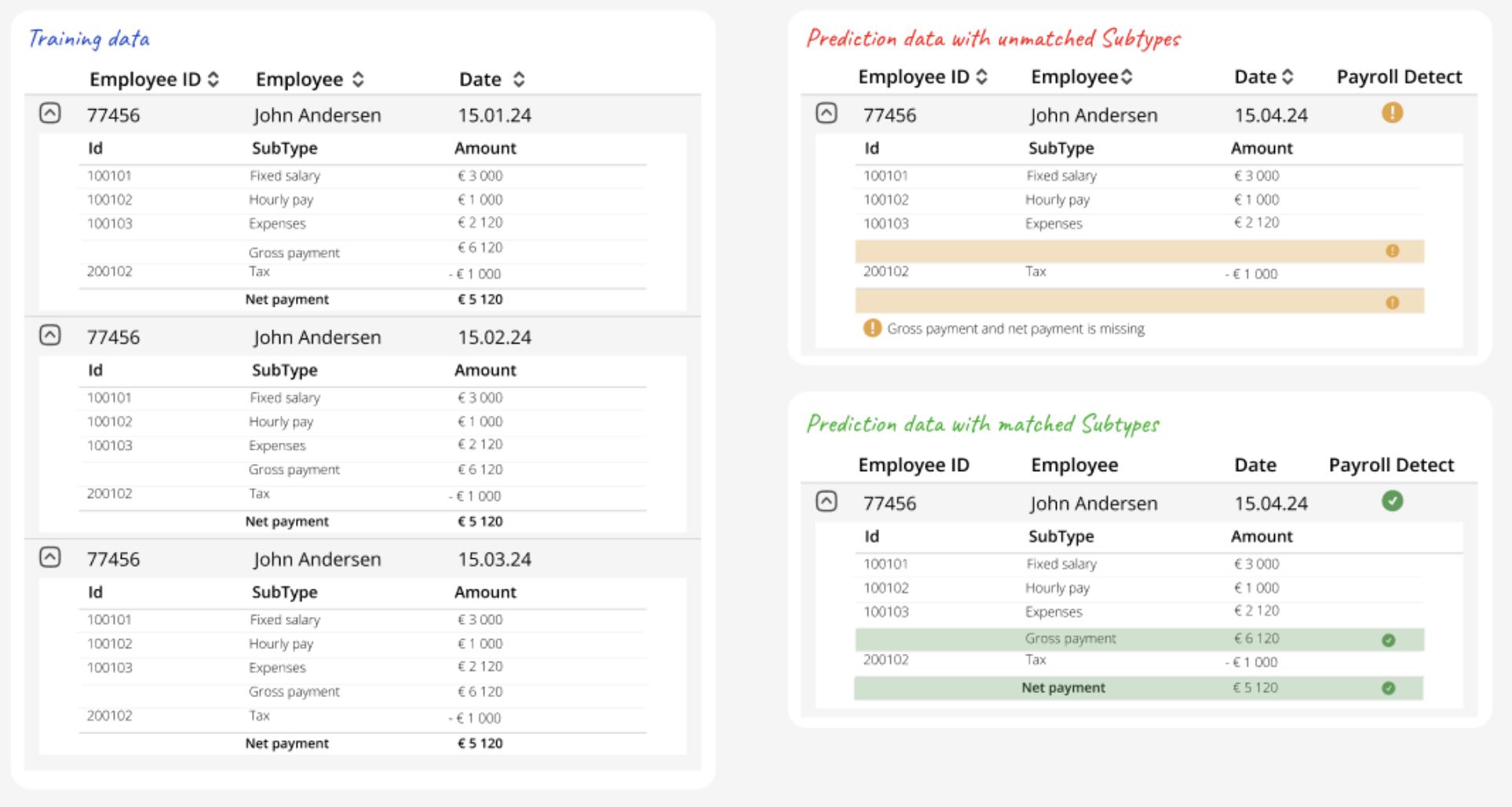
Different level of aggregation
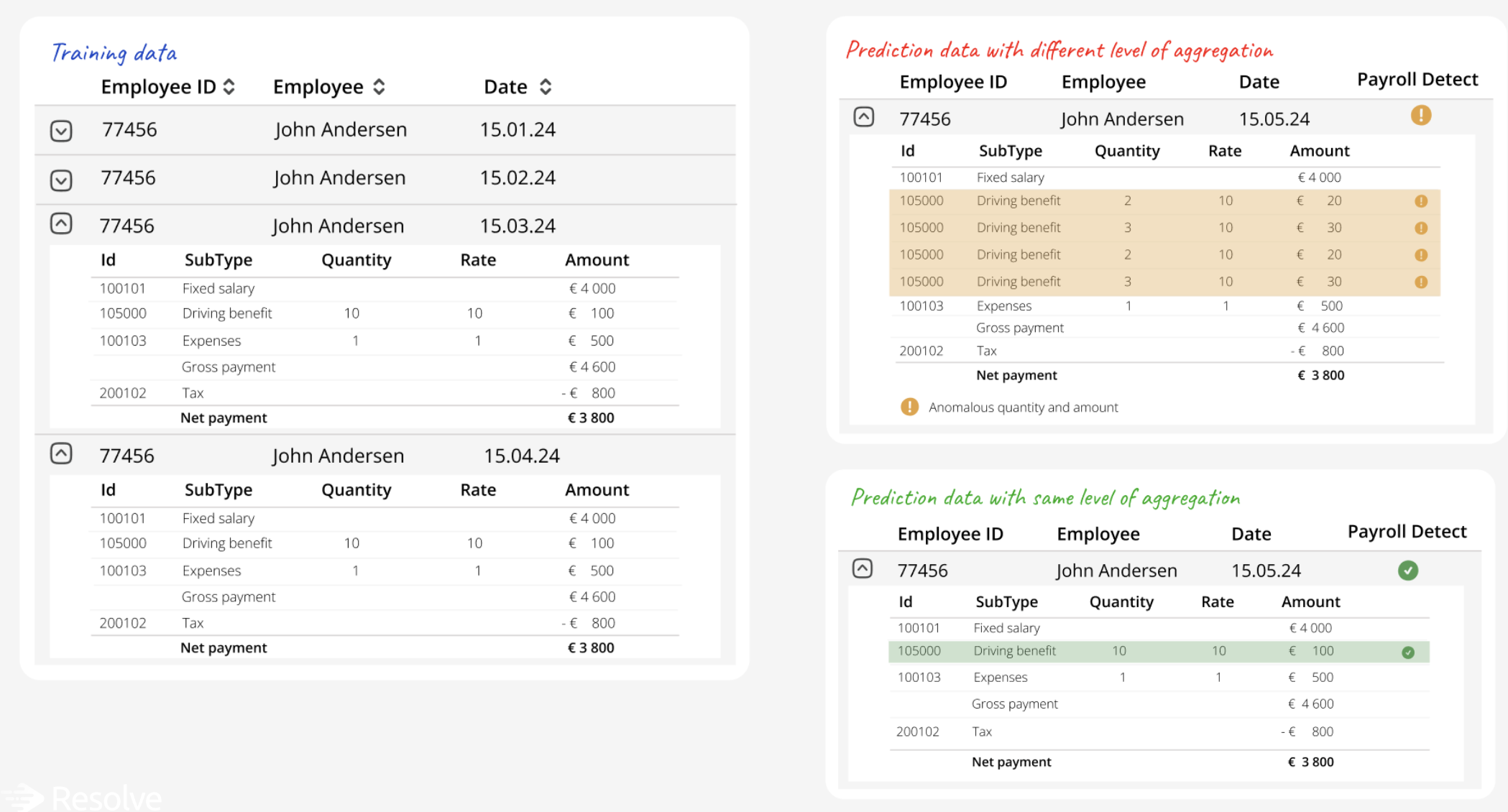
Fluctuating rates
Non-null blanks
Payslips
PayrollDetect dataset schema
required | Array of objects (Raw Data Upload Request Dataset) non-empty Datasets containing raw data for training. |
object Details for the webhook endpoint to call when a job finishes. |
{- "datasets": [
- {
- "id": "6180934d-044e-48e0-9b70-e1498fcf417e",
- "customerId": "string",
- "payslips": [
- {
- "id": "a10ba26d-1d90-409e-ae19-624fb16bf551",
- "date": "2024-05-21",
- "employeeId": "9053ad3a-b930-4637-bf14-0c23d7198aed",
- "employeeGroups": [
- "Engineering",
- "Intern"
], - "transactions": [
- {
- "id": "53c1ec4e-c2b9-4621-a7a9-00d93761f3d3",
- "contractId": "9053ad3a-b930-4637-bf14-0c23d7198aed",
- "type": "overtime",
- "subType": "incomeTax",
- "amount": 1000,
- "unit": "EUR",
- "fromDate": "2024-05-01",
- "toDate": "2024-05-31",
- "rate": 200,
- "quantity": 5,
- "costUnits": [
- {
- "department": "Engineering",
- "project": "Project X",
- "location": "Stockholm"
}, - {
- "company": "Company ABC"
}
]
}
]
}
]
}
],
}Each dataset contains a list of payslips. A payslip represents the payments relevant to an employee for a given period, where the transactions are the various elements that combine to determine the employee's payment.
All ids in the dataset needs to be globally unique. This includes ids for both transactions and payslips.
Payslip dates must fall within 20 years in the past to 1 year in the future from the current date. Dates outside this range will result in validation errors.
Employee groups
This field is for categorizing employees into different groups, which can be based on their department (like "Management," "Engineering," or "Sales") or their level within the organization (for example, L2, L3, L4). It's advised to use this feature to only include essential distinctions and to keep the number of different groups to a minimum. This simplification helps models to learn and better utilize this information.
Since employees have a varying number of payslips, the groups are used for the models to learn patterns across multiple employees. While limiting the number of groups is advised, it is also beneficial to group employees with similar characteristics. The similarity between employees is something the models will learn, enhancing their performance.
Transactions
A transaction in the context of PayrollDetect is a detailed record of a single salary-related entry within a payslip. Each transaction includes essential information such as the type and subtype of the transaction, the amount, quantity and/or rate. It also specifies the start and end dates for the transaction. Additionally, transactions can be associated with various cost units that describe the allocation of the transaction.
Transactions have the fields amount, rate and quantity. For each transaction, at least one of these fields needs to be present and non-zero. These fields also has a maximum and minimum value requirements, where the minimum value is currently set to -10 000 000, and maximum set to 10 000 000.
Transaction fromDate and toDate fields must fall within 20 years in the past to 2 years in the future from the current date. Dates outside this range will result in validation errors.
Each payslip has a limit on the number of transactions that can be present. Maximum number of transactions is currently set to 100, but we strongly advice to keep the number of transactions per payslip way lower.
It is recommended to maintain data at an aggregated level to avoid the inclusion of excessively granular details, such as individual daily time registrations. Such specificity reduce the performance of the models. A preferable approach is to consolidate data, for example, summarizing an employee’s total hours worked across the entire payslip period, like a month. This strategy enhances clarity and utility, ensuring that payroll transactions are both comprehensive and relevant.
Type
The type of the transaction, e.g. net, gross, tax, etc. This fields groups the various transactions into categories that is used for the model to learn patterns of similar transactions.
SubType
The sub-type of the transaction, e.g. if transactionType is tax, then subtype could be "1293" or "income tax". This is a more granular division of transactions.
- Gross Wages: The total amount of money earned by an employee before any deductions are made.
- Net Pay: The amount of money an employee takes home after all deductions are made from the gross wages.
- Various Deductions: Amounts subtracted from the gross wages for various reasons, such as taxes (income tax, Social Security), retirement contributions, and other withholdings (health insurance premiums, union dues, child support).
- Salary Payments: Compensation paid to employees on a regular basis, typically monthly, bi-weekly, or weekly.
- Supplemental Earnings and Benefits: I.e Bonuses or holiday pay.
Data Upload
When using our API to upload data, it's important to understand how we process data in our system.
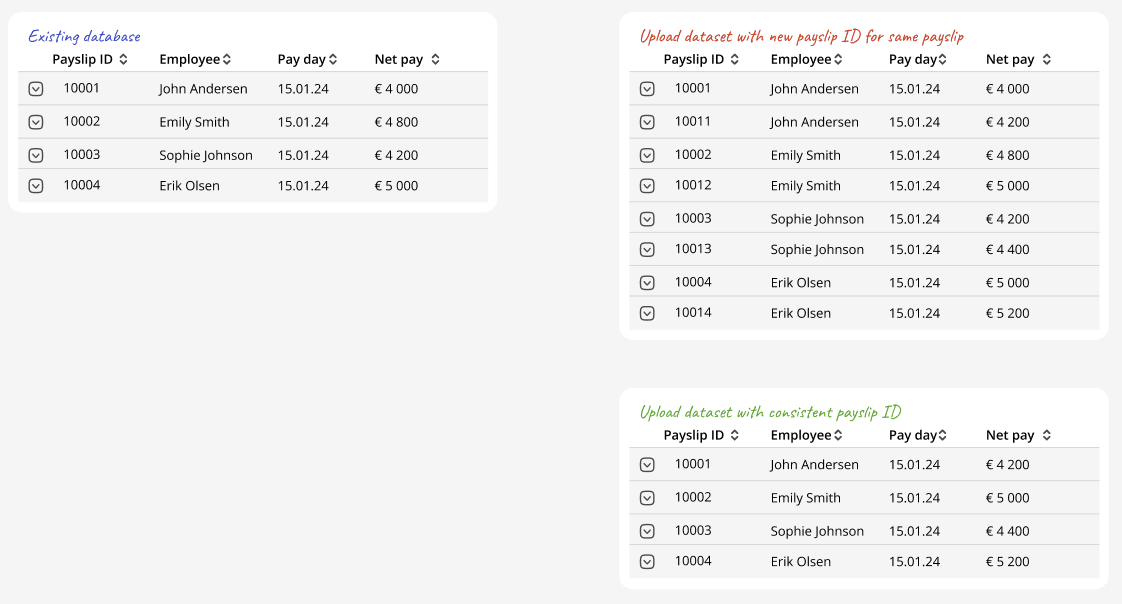
We process data by checking if the payslipId already exists in our database. If the payslipId is not present, the payslip is added to our database and will be used for training.
Logic flow diagram
To prevent issues, partners should adhere to one of the following practices:
-
Upload Only New Data: Ensure that only new or updated training data is uploaded during each session. This minimizes the risk of duplicating existing records and reduces the size of the database.
-
Use Consistent IDs: Maintain consistent
payslipIdvalues for the same records across multiple uploads. For example, ensure that the payslip for month A for employee B is always identified by the same ID (e.g., ID C). This practice prevents the system from treating the same record as a new entry, thereby avoiding duplication.
Example of consistent/inconsistent IDs